
Heart disease classification using data science tools – a review and hands-on
Artikel ini ditulis dan dianalisis oleh Suripto, Rr Nurul Rahmanita dan Ajeng Sekar Kirana, ketiganya merupakan mahasiswa S2 Teknik Industri, Binus University.
Heart disease classification sangat memungkinkan untuk dianalisis menggunakan teknik-teknik data science yang telah didiskusikan pada mata kuliah Selected topic in Industrial Engineering. Artikel yang akan direview dan direplikasi teknik-tekniknya berjudul: Heart disease classification using data mining tools and machine learning techniques, ditulis oleh Tougui, Jilbab, El-Mhamdi 2020 pada jurnal health and technology.
Berikut ini adalah perbedaan hands-on yang telah dilakukan mengikuti hasil diskusi di kelas:
| artikel | review dan hands on |
| Membandingkan dengan berbagai aplikasi seperti Orange,Weka, Rapidminer, knime, matlab dan scikit-learn | menggunakan orange data mining apps. |
| Membandingkan Teknik machine learning yaitu Logistic Regression, SVM, KNN, ANN,Naïve bayes dan Random Forest | Membandingkan Teknik machine learning yaitu Logistic Regression, SVM, KNN, Naïve bayes dan Random Forest (pada Orange tidak terdapat menu ANN |
| Membahas mengenai heart diseases classification prediction | Membahas mengenai heart diseases classification prediction |
Prediksi Gagal Jantung Menggunakan Software ORANGE Data Mining
Contoh sample data diambil dari situs Kaggle.com dengan Topik Heart Failure Prediction Dataset.
Penyakit kardiovaskular (CVD) adalah penyebab kematian nomor 1 secara global, mengambil sekitar 17,9 juta nyawa setiap tahun, yang menyumbang 31% dari semua kematian di seluruh dunia. Empat dari kematian 5CVD disebabkan oleh serangan jantung dan stroke, dan sepertiga dari kematian ini terjadi sebelum waktunya pada orang di bawah 70 tahun. Gagal jantung adalah peristiwa umum yang disebabkan oleh CVD dan dataset ini berisi 11 fitur yang dapat digunakan untuk memprediksi kemungkinan penyakit jantung.
Orang dengan penyakit kardiovaskular atau yang berisiko kardiovaskular tinggi (karena adanya satu atau lebih faktor risiko seperti hipertensi, diabetes, hiperlipidemia atau penyakit yang sudah mapan) memerlukan deteksi dini di mana model pembelajaran mesin dapat sangat membantu. Informasi attribut data adalah sebagai berikut:
- Usia: usia pasien [tahun]
- Jenis kelamin: jenis kelamin pasien [M: Pria, F: Wanita]
- ChestPainType: tipe nyeri dada [TA: Angina Khas, ATA: Angina Atipikal, NAP: Nyeri Non-Anginal, ASY: Asimptomatik]
- RestingBP: mengistirahatkan tekanan darah [mm Hg]
- Kolesterol: kolesterol serum [mm/dl]
- FastingBS: gula darah puasa [1: jika FastingBS > 120 mg/dl, 0: sebaliknya]
- RestingECG: hasil elektrokardiogram istirahat [Normal: Normal, ST: memiliki kelainan gelombang ST-T (inversi gelombang T dan / atau elevasi ST atau depresi > 0,05 mV), LVH: menunjukkan kemungkinan atau pasti hipertrofi ventrikel kiri dengan kriteria Estes]
- MaxHR: detak jantung maksimum tercapai [Nilai numerik antara 60 dan 202]
- ExerciseAngina: angina yang diinduksi latihan [Y: Ya, N: Tidak]
- Oldpeak: oldpeak = ST [Nilai numerik diukur dalam depresi]
- ST_Slope: kemiringan segmen ST latihan puncak [Atas: upsloping, Datar: datar, Bawah: downsloping]
- HeartDisease: kelas keluaran [1: penyakit jantung, 0: Normal]
Sumber data
Himpunan data ini dibuat dengan menggabungkan himpunan data berbeda yang sudah tersedia secara independen tetapi tidak digabungkan sebelumnya. Dalam himpunan data ini, 5 himpunan data jantung digabungkan lebih dari 11 fitur umum yang menjadikannya kumpulan data penyakit jantung terbesar yang tersedia sejauh ini untuk tujuan penelitian. Lima himpunan data yang digunakan untuk kurasinya adalah:
- Cleveland: 303 pengamatan
- Hongaria: 294 pengamatan
- Swiss: 123 pengamatan
- Long Beach VA: 200 pengamatan
- Kumpulan Data Stalog (Heart): 270 pengamatan
Total: 1190 pengamatan
Duplikat: 272 pengamatan
Final dataset: 918 observations
Pengolahan data
Pengolahan data pada Tugas kelompok ini menggunakan bantuan software ORANGE dengan dataset yang diunduh dari Kaggle.com dengan nama file “Heart Failure Prediction”. Pada pengolahan dataset ini, akan membandingkan metode algoritma SVM (Support Vector Machine), Naïve Bayes Classifier , Tree, Random Forest, KNN dan Logistic Regression. Diakhir dari tugas ini akan diketahui algoritma mana yang lebih tinggi tingkat CA (Classification Accuracy) nya. File data dalam bentuk file csv. Seperti pada Gambar di bawah ini. Pada kolom nama (Heart Disease) harus diubah menjadi target (pada kolom Role). Penentuan target ini penting dilakukan supaya proses data bisa berhasil.
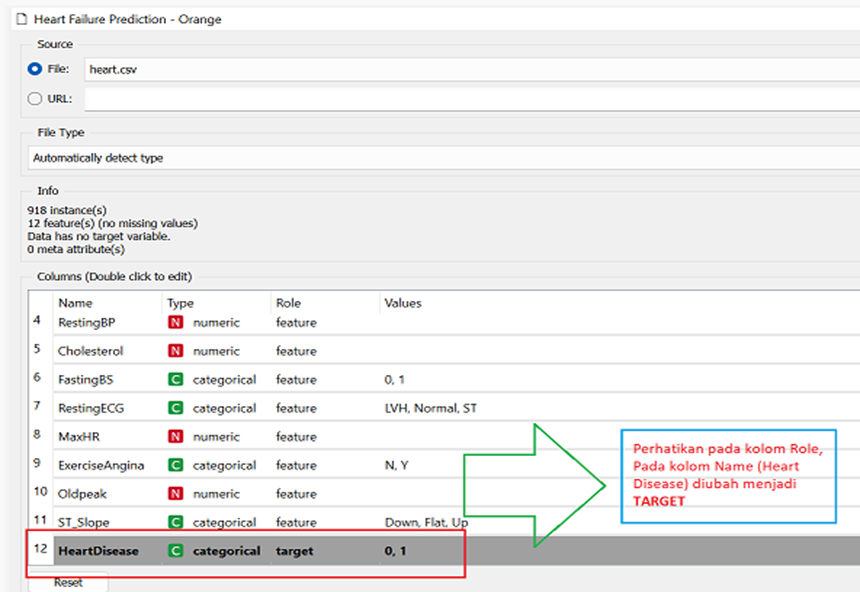
Gambar: Data attribute untuk pre-process
Framework orange data mining untuk pengembangan model dapat dilihat pada Gambar berikut ini:
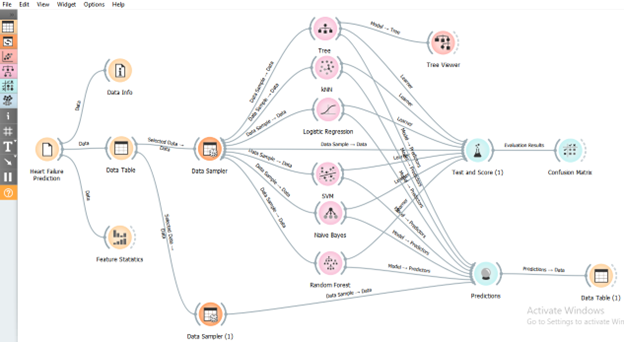
Gambar: Orange data mining framework
Decision tree model
Decision tree adalah algoritma machine learning yang menggunakan seperangkat aturan untuk membuat keputusan dengan struktur seperti pohon yang memodelkan kemungkinan hasil, biaya sumber daya, utilitas dan kemungkinan konsekuensi atau resiko. Konsepnya adalah dengan cara menyajikan algoritma dengan pernyataan bersyarat, yang meliputi cabang untuk mewakili langkah-langkah pengambilan keputusan yang dapat mengarah pada hasil yang menguntungkan.
Tree merupakan struktur data yang biasanya tidak kontigu, dimana sebuah node bisa memiliki beberapa “anak” (child node), dan berbeda dengan Graph, jalan menuju sebuah child node hanya bisa dicapai melalui maksimal 1 node, dimana pada Graph, dimungkinkan bahwa 1 node bisa dicapai dari banyak node lainnya. Sebuah node yang tidak memiliki child node sama sekali dinamakan leaf node.
Support Vector Machine
Algoritma Support Vector Machine merupakan salah satu algoritma yang termasuk dalam kategori Supervised Learning, yang artinya data yang digunakan untuk belajar oleh mesin merupakan data yang telah memiliki label sebelumnya. Sehingga dalam proses penentuan keputusan, mesin akan mengkategorikan data testing ke dalam label yang sesuai dengan karakteristik yang dimiliki nya.
Cara kerja dari metode Support Vector Machine khususnya pada masalah non-linear adalah dengan memasukkan konsep kernel ke dalam ruang berdimensi tinggi. Tujuannya adalah untuk mencari hyperplane atau pemisah yang dapat memaksimalkan jarak (margin) antar kelas data. Untuk menemukan hyperplane terbaik, kita dapat mengukur margin kemudian mencari titik maksimalnya. Proses pencarian hyperplane yang terbaik ini adalah ini dari metode Support Vector Machine ini.
Naive Bayes Classifier
Naive Bayes adalah algoritma machine learning untuk masalah klasifikasi. Ini didasarkan pada teorema probabilitas Bayes. Hal ini digunakan untuk klasifikasi teks yang melibatkan set data pelatihan dimensi tinggi. Beberapa contohnya adalah penyaringan spam, analisis sentimental, dan klasifikasi artikel berita.
Tidak hanya dikenal karena kesederhanaannya, tetapi juga karena keefektifannya. Sangat cepat untuk membangun model dan membuat prediksi dengan algoritma Naive Bayes. Naive Bayes adalah algoritma pertama yang harus dipertimbangkan untuk memecahkan masalah klasifikasi teks.
Random forest
Random forest (RF) adalah suatu algoritma yang digunakan pada klasifikasi data dalam jumlah yang besar. Klasifikasi random forest dilakukan melalui penggabungan pohon (tree) dengan melakukan training pada sampel data yang dimiliki. Penggunaan pohon (tree) yang semakin banyak akan mempengaruhi akurasi yang akan didapatkan menjadi lebih baik. Penentuan klasifikasi dengan random forest diambil berdasarkan hasil voting dari tree yang terbentuk. Pemenang dari tree yang terbentuk ditentukan dengan vote terbanyak.
k-Nearest Neighbor
Algoritma k-Nearest Neighbor adalah algoritma supervised learning dimana hasil dari instance yang baru diklasifikasikan berdasarkan mayoritas dari kategori k-tetangga terdekat. Tujuan dari algoritma ini adalah untuk mengklasifikasikan obyek baru berdasarkan atribut dan sample-sample dari training data. Algoritma k-Nearest Neighbor menggunakan Neighborhood Classification sebagai nilai prediksi dari nilai instance yang baru.
Logistic Regrresion
Logistic regression adalah jenis analisis statistik yang sering digunakan data analyst untuk pemodelan prediktif. Dalam pendekatan analitik ini, variabel dependennya terbatas atau kategoris, bisa berupa A atau B (regresi biner) atau berbagai opsi hingga A, B, C atau D (regresi multinomial). Jenis analisis statistik digunakan dalam software statistik untuk memahami hubungan antara variabel dependen dan satu atau lebih variabel independen dengan memperkirakan probabilitas. Jenis analisis ini dapat membantu Anda memprediksi kemungkinan.
Akurasi model
Hasil akurasi , presisi, recall dan AUC pada setiap model machine learning dapat dilihat pada Gambar berikut ini:
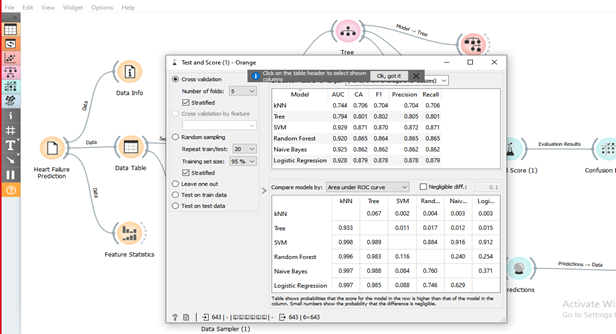 Gambar: Kinerja model machine learning
Gambar: Kinerja model machine learning
 Gambar: Validasi model dengan data testing
Gambar: Validasi model dengan data testing
Kesimpulan
Hasil dari Test and score ini dengan melakukan pengulangan sebanyak 20 kali dan menggunakan 95 % dari jumlah data. Hasil dari pengujian ini menunjukkan bahwa metode Logistic Regression memiliki tingkat Classification Accuracy (CA) tertinggi sebesar 87,9%, dan CA terendah adalah algoritma KNN dengan persentasi 70,6%.
Data prediksi kegagalan jantung (Heart Failure Prediction) yang dilakukan, proses data menunjukkan bahwa nilai CA yang tidak jauh berbeda antara beberapa algoritma. Untuk lebih memastikan nilai CA lebih presisi, perlu dilakukan proses data dengan algoritma lainnya.
Dataset yang diunduh dari Kaggle.com setelah dilakukan Test and Score, mendapatkan nilai CA kurang dari 90%, hal ini harus diteliti lebih jauh apakah metode pengambilan sample sudah akurat dan presisi.
Hasil function prediction pada software Orange menunjukkan bahwa algoritma Tree memiliki nilai CA prediksi paling tinggi diantara algoritma lainnya yaitu 96%, sementara algoritma terendah pada prediction yaitu algoritma KNN dengan persentasi 80.2%.